
Фото из сети Интернет
Более 50 лет существования интернета подарили огромный объем контента, размещенного на страницах сайтов. Несмотря на то, что многие уже не существуют, сегодня можно получить доступ к информации, которая содержалась на веб-ресурсах много лет назад. Это становится возможным благодаря архивации данных на открытой платформе, которая называется Wayback Machine. Сервис использует для хранения данных более 750 выделенных серверов, установленных в четырех дата-центрах, на которых сейчас заархивировано около 625 млрд страниц контента. Сегодня интернет-архив позволяет проникнуть в прошлое и узнать, какой контент и дизайн страниц были популярны в разные периоды.
 Интересным веб-архивом будет и для простых пользователей. Хотите узнать о том, как выглядела поисковая система Google или соцсеть Facebook на начальном этапе создания? Отправиться в прошлое интернет и увидеть, каким он был 15-20 лет назад? Это доступно любому, кто имеет компьютер и подключение к сети.
Интересным веб-архивом будет и для простых пользователей. Хотите узнать о том, как выглядела поисковая система Google или соцсеть Facebook на начальном этапе создания? Отправиться в прошлое интернет и увидеть, каким он был 15-20 лет назад? Это доступно любому, кто имеет компьютер и подключение к сети.
Но прежде чем использовать веб-архив Wayback Machine, следует поговорить об истории создания самого инструмента .
Как была разработана программа Wayback Machine
Проблема хранения информации в интернете беспокоила изобретателей веб-архива Кале и Джиллиата с конца 90-х годов прошлого века. Это связано с тем, что контент на сайтах исчезает, когда владелец больше не может оплачивать домен и хостинг, или по каким-то причинам решил удалить веб-ресурс. Книги, фильмы или газеты могут храниться в библиотечных архивах, ведь носят материальный характер, однако доступ к онлайн-информации на тот момент был возможен только в режиме реального времени.
В начале двухтысячных лет энтузиастами была создана компания Internet Archive, преследовавшая большую цель — осуществить архивирование информации по всему интернету. Некоммерческая организация была зарегистрирована в 2001 году, при этом за 5 лет до этого уже существовал проект поиска и хранения информации под названием Wayback Machine. На момент торжественного открытия компании учредителям уже было что показать общественности.
После пяти лет функционирования Wayback Machine насчитывал более 10 млрд. страниц, а после 2020 года наполнение архива пересекло отметку в 70 петабайдов. К примеру, в одном петабайте содержатся 1024 терабайта информации. Зачем нужен интернет-архив
Этот инструмент очень полезен для веб-специалистов. В веб-архив дополнительно разработан специальный поисковый робот, автоматически просматривающий страницы сайтов и хранящий материалы.
Сканирование краулера Wayback Machine осуществляется по своему графику и косвенно зависит от регулярности и количества обновлений информации на веб-ресурсах. Чем чаще обновляется контент, тем чаще на сайт будет заходить краулер.
Для чего нужен архив Wayback Machine:
- веб-архивом следует воспользоваться перед заказом доменного имени. При регистрации домена владелец не знает, было ли это имя в использовании до того. Но эта информация открыта — с помощью сервиса Whois можно узнать время создания домена, а в веб-архиве — увидеть контент, который был размещен на нем раньше. Это очень ценная информация, ведь история домена влияет на его продвижение.
- для проверки доменов-доноров перед получением бэклинков с целью развития ссылочного профиля своего сайта. Сотрудничество с веб-ресурсами, имеющими хорошую историю, может значительно усилить позиции в поисковике. При этом ссылка из старых трастовых доменов Google оценивает выше, чем из молодых.
- с целью получения информации об истории развития интернета. Общая задача веб-архива — это исследование. Wayback Machine является очень большим источником информации, в который входят наиболее актуальные данные не только прошлого, но и настоящего. Например, можно посмотреть, какой дизайн имели сайты на рассвете своего существования или найти удаленный контент.
Как работать с Wayback Machine
В первую очередь нужно перейти на главный сайт веб-архива web.archive.org. Использование сервиса достаточно просто: необходимо только ввести адрес сайта, который вы планируете исследовать, в поисковую форму.
Результатом выдачи станет информация о графике активности краулера, размещенной в верхней части сайта. Несколько ниже пользователь сможет увидеть календарь, в котором отмечены данные о фиксации снапшотов (снимков системы файлов). Информация о сайте доступна только за дни, отмеченные кругами синего и зеленого цвета. Для получения более подробной информации о состоянии веб-ресурса необходимо выбрать один снапшот и кликнуть на него. Например, так выглядит календарь активности краулера на страницах Facebook в 2022 году.
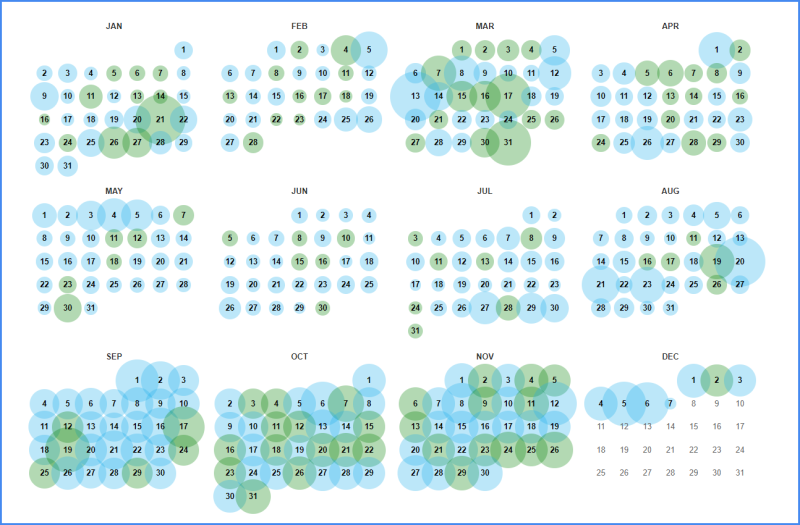
На сохраненных сайтах функционирует вся навигация, поэтому можно походить по страницам и посмотреть функционал и наполнение старой версии.
Прочие материалы в Internet Archive
Стоит отметить, что Web-archive является частью крупного проекта Internet archive. Платформа хранит не только информацию с сайтов, но и другие материалы, когда-либо публиковавшиеся в сети. Это так называемые «цифровые артефакты», к которым относятся видео, текст, аудио, приложения и картинки.
Интернет-архив позволяет ознакомиться с таким контентом как аудиокниги (преимущественно на английском языке), документальные фильмы, радиопередачи, архивные новости из газет и телевидения, музыкальные записи и другие данные, которые могут заинтересовать любого исследователя. Очень познавательный раздел с программным обеспечением, в котором можно найти старые игры и программы, которые еще устанавливались с дискет. , 4 млн картинок, почти 8 миллионов программ, 14 млн аудиофайлов и более 7 млн видео.
Но в архиве можно увидеть не только старые данные возрастом в 10 , 20 или даже 100 лет, но и современные материалы. Ведь проект и разор продолжает развиваться и сохранять терабайты информации, которая в будущем также станет историей.